Tecnologia
A frota que se construiu sozinha — e depois construiu nossos agentes
Building in public. Como nasceu o dev-fleet, o que quebrou no caminho, e o teste que realmente importava: usá-lo, ainda instável, para construir o cérebro dos agentes do Lab019.
O gargalo é você
Se você usa Claude Code, Cursor ou Aider, já sentiu os dois lados da mesma moeda. O ganho: um agente escreve código de verdade, rápido. E o teto: você continua sendo o gargalo. Cada tarefa é você abrindo o editor, escolhendo o agente, vigiando o output, decidindo o próximo passo. Os PRs empilham esperando review. Os bugs esperam alguém ter tempo. O refactor prometido vira parking lot eterno. Você sabe o que precisa ser feito — só não consegue paralelizar com você mesmo.
A pergunta que originou o dev-fleet foi exatamente essa: se você pudesse rodar quatro versões de você mesmo, cada uma concentrada numa tarefa diferente, ao mesmo tempo, quantas releases você faria por semana?
E se você é quem responde pelo roadmap, esse gargalo tem outro nome: time-to-market. Cada item parado no backlog é receita adiada, um concorrente que chega primeiro, um cliente que esperou demais. Multiplicar seus melhores engenheiros por quatro não é fantasia de produtividade — é a diferença entre lançar neste trimestre e lançar no ano que vem.
Este texto conta como respondemos a essa pergunta construindo o dev-fleet — e por que a prova final não foi um tutorial de brinquedo, mas o runtime de produção que vai rodar os próprios agentes do Lab019.
A frota: o que é o dev-fleet
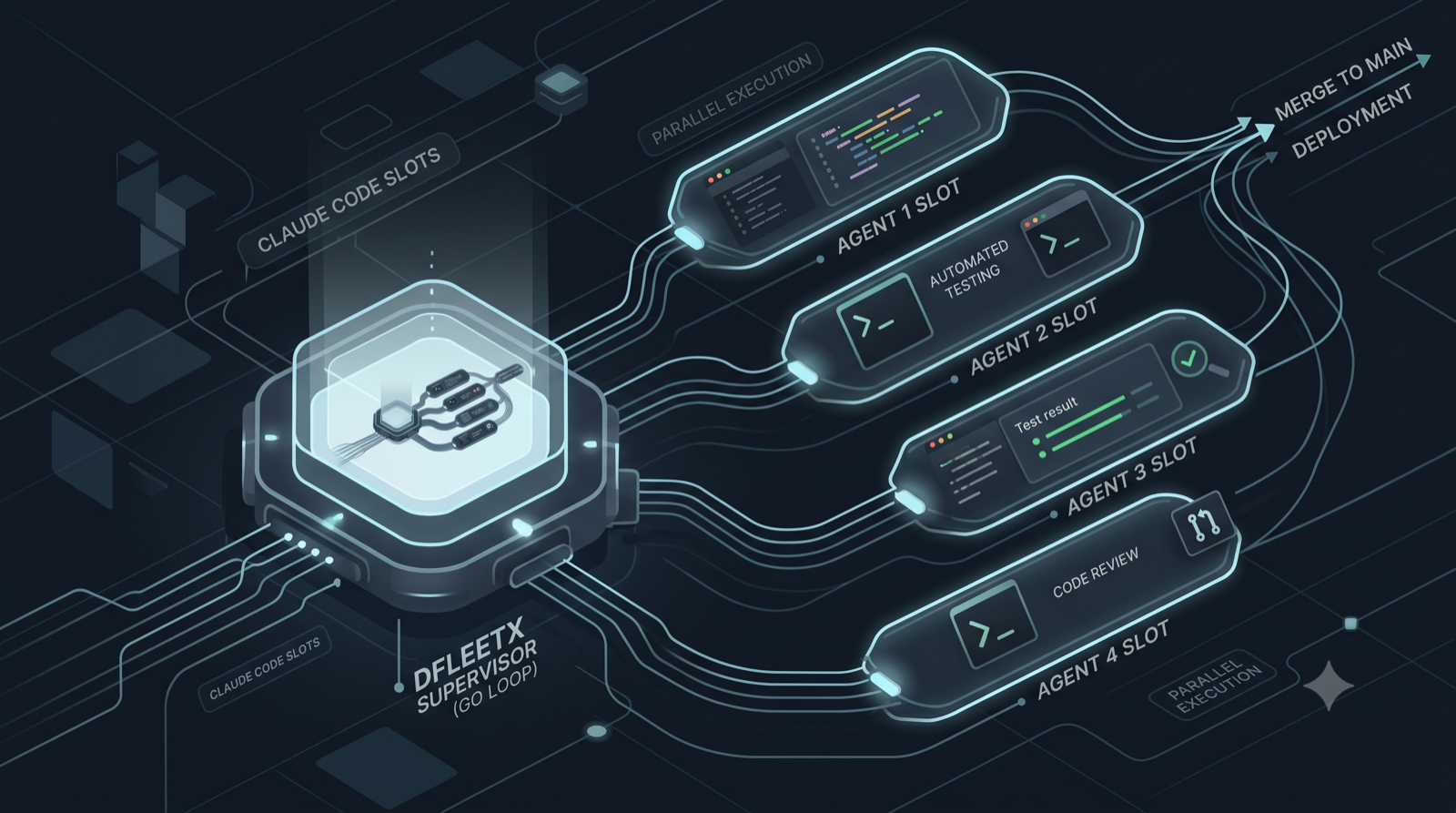
O dev-fleet é um sistema de orquestração que pega histórias de software já especificadas e as implementa de ponta a ponta — escreve o código, testa, abre o PR, faz o code review e o merge — sem que o operador humano precise escrever uma linha durante a implementação.
E não pense numa fábrica de software: linha de montagem é repetição mecânica, e disso o mundo já tem de sobra. Pense numa frota de agentes autônomos. O operador define a missão — requisitos, arquitetura, a lista de épicos e histórias — e despacha. Cada agente assume uma história e a leva sozinho do início ao fim: escreve, testa, revisa o próprio código, abre o PR, faz o merge. O operador comanda de longe; não pilota nenhum deles, e nenhum precisa dele a cada passo.
O binário se chama dfleetx, e ele coordena três peças:
- Slots — sessões persistentes do Claude Code rodando em git worktrees isoladas, uma por história em implementação. Cada slot escreve código, parseia output, faz julgamentos. É, por natureza, não-determinístico.
- Supervisor — um loop determinístico, em Go, que lê o estado de cada slot, decide o próximo prompt, faz o merge quando a história termina e registra tudo num journal. Quando o output do slot é ambíguo demais para uma regra fixa, ele aciona um agent-supervisor (uma LLM) que lê o resultado e emite o veredito.
- BMAD — a cadeia canônica de skills (
/bmad-prd → /bmad-create-architecture → /bmad-create-epics-and-stories) que transforma um objetivo em linguagem natural num PRD, uma arquitetura e uma lista de épicos e histórias.
Do ponto de vista de quem usa, são três passos. Você faz o setup uma vez (dfleetx init cria o workspace versionado). Você escreve o plano — um PRD, que a cadeia BMAD desdobra em arquitetura, épicos e histórias; em seguida o dfleetx plan from-epics compila isso num sprint-status.yaml com 5 a 15 histórias, já com as dependências e prioridades que governam a ordem de execução. E você dá o dispatch:
dfleetx run-sprint --max-parallel 4A partir daí, você pode dormir. Até quatro agentes trabalham em paralelo em histórias independentes. Cada um provisiona seu worktree, elabora a spec, escreve os testes de aceitação primeiro e implementa até passarem — o ATDD que o BMAD impõe —, passa o código por um agente de code review, abre o PR, espera o CI ficar verde e faz o merge na main. Se o pipeline falha, o agente tenta se autocorrigir. Se há conflito de merge, o supervisor faz auto-rebase e tenta de novo. Se algo realmente quebra, o supervisor marca aquela história como “precisa de revisão” e segue com as próximas — não cancela o lote. Quando você acorda, está tudo revisado e merged — com a trilha de cada PR registrada, caso você queira inspecionar. O único limite que sobra é o que você escolher: se o pipeline da sua main faz deploy contínuo, a frota vai até produção sozinha; se não, o merge na main é o ponto em que você decide quando promover. Na prática, é isso que comprime o calendário: o que sairia em série, uma feature por vez, sai como um lote — entregas na mesma semana, não no próximo trimestre.
A diferença em relação ao que você já conhece é de categoria, não de grau. Claude Code é um operador solo: você decide, o agente executa. O dev-fleet comanda a frota inteira — coordena vários Claude Code ao mesmo tempo, mantendo estado, resolvendo dependências e conflitos. Não é um fluxo pré-programado como n8n ou Zapier — a topologia (o que roda em paralelo, o que roda em série) emerge das dependências que você declarou no plano. E não é uma biblioteca de primitivas multi-agente como CrewAI ou AutoGen, com a qual você constrói seu próprio sistema — o dev-fleet é o sistema, opinativo, com defaults seguros e uma disciplina canônica embutida.
Há um detalhe que muda tudo para quem tem propriedade intelectual a proteger ou dados sob LGPD: o dev-fleet roda dentro da sua infraestrutura. Nas máquinas dos seus desenvolvedores ou em VMs na sua nuvem — o código-fonte, os tokens e o tráfego nunca saem do seu ambiente. Não há repositório enviado para um serviço de terceiros; a frota trabalha onde o seu código já vive. Para propriedade intelectual e para LGPD, isso não é um recurso opcional: é a diferença entre poder usar a ferramenta e não poder.
E porque cada decisão passa pelo journal, o subproduto é uma trilha de auditoria completa — qual slot pegou qual história, qual PR saiu, qual foi o veredito do agent-supervisor, o que falhou e como foi recuperado, tudo registrado de forma append-only e reconstruível. Para um comitê de risco avaliando IA que escreve código, isso responde de imediato à única pergunta que de fato trava a adoção: quem fez o quê, quando, e como eu provo isso depois?
41 horas em público — o ápice de dezessete dias
O dev-fleet não nasceu do nada. Ele veio do fsaap-workspace — um conjunto de scripts shell e skills BMAD que comecei a montar em meados de abril de 2026 para coordenar agentes Claude pelos dezesseis repositórios da plataforma do Lab019: lançar sessões em tmux, abrir um worktree git por história, despachar, organizar branches, fazer merge. Foi o meu primeiro ensaio de automação — uns 330 commits de uma engenhoca que funcionava muito bem para uma pessoa só: eu. O problema é que era inseparável do meu setup e da minha cabeça; ninguém mais conseguiria operar aquilo. O dev-fleet é o passo seguinte: pegar as lições daquele ensaio e consolidá-las num formato de aplicação — um binário, dfleetx, que outra pessoa instala e usa sem ter que me levar junto.
A forma final, então, não veio de um diagrama nem de uma noite de sorte. O primeiro commit do dfleetx é de 20 de maio de 2026 — praticamente quando o fsaap-workspace recebeu seus últimos retoques. De lá para cá foram dezessete dias e cerca de 1.300 commits, e não numa linha reta: houve dias de mais de cem commits e houve dias de quase nada — parado, depurando, desfazendo decisão ruim, esperando o entendimento alcançar a pressa. O que aconteceu entre 4 e 6 de junho foi o ápice dessa curva: uma sessão de ~41 horas em que o dev-fleet, já maduro o bastante, foi virado contra si mesmo — usado para construir a si mesmo. A curva de commits no repositório conta essa história melhor que qualquer adjetivo:

E o ápice — a sessão de 4 a 6 de junho — rende os números que transformam o experimento em proposta, anotados enquanto ela acontecia:

Um detalhe muda completamente a leitura desse custo. Os ~US$ 650 são o preço-equivalente de API — o que sairia se cada token fosse cobrado pela tabela da Anthropic. Não foi isso que pagamos. O dev-fleet roda sobre uma assinatura Claude Max de US$ 200/mês, e esta sessão inteira — as 189 histórias — consumiu menos da metade da quota mensal dessa assinatura. O desembolso real, portanto, não foram US$ 650: foram os US$ 200 do mês, com quota de sobra para repetir tudo de novo antes de a fatura virar.
Vale traduzir esses números, porque é aqui que o experimento vira proposta — e vale fazer a conta no agregado, com honestidade. Foram 189 histórias — e não exercícios de demonstração: features, correções e refactors reais que entraram no próprio dev-fleet e estão rodando. É engenharia de verdade, do tipo que você pagaria para ter. À taxa em que um bom engenheiro fecha de uma a duas histórias por dia, isso representa de 95 a 189 dias-pessoa de trabalho — entre quatro e nove meses de um engenheiro full-time, ou um time pequeno ocupado por um trimestre. A um custo de engenharia da ordem de US$ 30/hora no Brasil, esse escopo sairia por algo entre US$ 23 mil e US$ 45 mil.
O dev-fleet entregou o mesmo volume em ~41 horas de relógio. Mesmo pelo preço-cheio de API, os ~US$ 650 seriam menos de 3% do custo humano; pelo desembolso real — os US$ 200 da assinatura do mês — fica abaixo de 1%. De qualquer ângulo, é trabalho de meses entregue em dois dias por uma fração mínima do custo de engenharia equivalente. É essa compressão dupla — de calendário e de custo — que muda a conversa para quem responde pelo orçamento e pelo time-to-market.

E aqui vale neutralizar a objeção óbvia — “mas você rodou quatro em paralelo”. Rodei; então a comparação justa é contra quatro engenheiros em paralelo, não contra um. O custo em dinheiro não muda com isso — você paga as mesmas pessoa-horas, só distribuídas em menos tempo. O que o paralelismo encurta é o calendário. E mesmo aí: quatro engenheiros, à mesma régua de uma a duas histórias por dia cada, fechariam as 189 histórias em cerca de um a dois meses e meio. A frota, com a mesma largura de quatro frentes, fechou em dois dias. A diferença vem de dois fatores que se combinam: cada frente leva ~25 minutos por história em vez de um dia inteiro; e cada frente trabalha 24x7, não 8x5 — mais de quatro vezes a janela semanal de um engenheiro (168 horas contra 40), e sem fins de semana. Trabalho que um time humano espalha por semanas, a frota faz numa madrugada — enquanto você dorme.

Três ressalvas, porque sem elas o número engana. Primeiro: as histórias variam de tamanho — várias são correções de um ou dois arquivos, então não leia “189 histórias” como “189 features grandes”. Segundo: isto foi o dev-fleet construindo a si mesmo, com 5,8% de histórias que falharam e precisaram ser recuperadas — não é uma promessa de 189 por noite no seu repositório. Terceiro: a frota pressupõe um CI confiável e um fluxo trunk-based — branches curtas que nascem da main e voltam para ela, com o pipeline verde como juiz que autoriza o merge. Sem testes que valham, não há sinal seguro; e git flow, com branches de release e de desenvolvimento de vida longa, não é suportado hoje. O argumento nunca foi “demita seus engenheiros”; é “multiplique os que você tem, deixe a frota revisar e mergear, e fique com a decisão que importa: o que vai para produção”.
A jornada teve uma virada clara. Nos primeiros dias, o operador rodava tudo com --max-parallel 1, por medo de conflitos de merge. E descobriu uma classe inteira de bugs de fragilidade: o supervisor perdia o rastro de um pipeline depois de um force-push e ficava horas lendo estado obsoleto; um slot retornava sem o marcador esperado e o supervisor ficava cego, em deadlock. O custo dessa descoberta foi de horas de relógio e estado de sprint corrompido — mas ela rendeu o primeiro insight que estruturou todo o resto:
O supervisor precisa ser determinístico — mas o que ele supervisiona não é. O loop que despacha, mergeia e registra é Go puro, previsível. O slot, do outro lado, é não-determinístico por natureza: escreve prosa, toma decisões, e o output dele nem sempre cabe numa regra fixa. O erro era forçar essa ponte com regex frágil — procurar “MERGED_AT” no texto do slot e quebrar quando ele variava. A solução tem duas pernas. Para fatos objetivos (a história foi mergeada?), o supervisor consulta uma fonte autoritativa direta, em vez de acreditar na prosa. E para os casos genuinamente ambíguos que sobram, ele chama um agent-supervisor: uma LLM que lê o output do slot e devolve um veredito estruturado. Esse veredito é a cola entre os dois mundos — converte o não-determinismo do slot num sinal discreto que o processo determinístico consegue consumir. Determinismo onde dá para tê-lo; julgamento agêntico, contido e auditável, só onde é inevitável.
Isso levou ao segundo insight, o mais importante da arquitetura. Qual é a fonte da verdade do estado? Minha intuição inicial estava errada — eu tratava o Bitbucket como fonte da verdade e o journal como cache. A correção que reescreveu tudo: o journal é a fonte da verdade única do dev-fleet. O Bitbucket é o sistema-de-registro dos fatos de versionamento, cacheados no journal; o reconciliador é um mecanismo de resiliência que reconstrói o cache, não uma segunda fonte da verdade. Com isso, o status de cada história deixou de ser um campo escrito em dois lugares — com a race condition que isso cria — e passou a ser uma propriedade computada, derivada do journal.
O terceiro insight foi sobre paralelismo. O medo de merge era o bug; o supervisor é o conserto. Uma vez que o auto-rebase passou a funcionar, os lotes seguintes rodaram com quatro agentes em paralelo praticamente sem incidente — um único conflito real na sessão inteira, resolvido em cinco minutos. Paralelismo não é o risco a evitar. É o produto.
O quarto insight foi sobre disciplina. A tentação de pular a cadeia BMAD e ir direto pro código é constante — eu mesmo tentei três vezes numa única sessão. E toda vez o resultado era o mesmo: spec rasa, código raso, bug recorrente reaparecendo com um novo número. Por isso a cadeia canônica virou parte do produto, não recomendação: uma skill em modo hard-fail que impede qualquer agente de pular o gate.
E há aí um efeito que vale ouro para quem desconfia de código gerado por IA: como o BMAD impõe ATDD, cada história nasce com seus testes de aceitação escritos antes da implementação, e o código é escrito para passar neles. Nada chega na main sem prova de que faz o que a spec pediu — é isso que torna o pipeline verde um juiz confiável, e não um carimbo. O código não sai só pronto; sai testado.
E o quinto insight é quase filosófico, mas teve consequências concretas: durante toda a sessão, o operador era um Claude testando o produto enquanto o construía. Cada fricção que eu sentia virava candidata a feature. O comando dfleetx status nasceu porque eu rodava de três a cinco comandos só para responder “qual é o estado?”. A sincronização automática com o Linear nasceu porque eu transcrevia a mesma tabela à mão a cada entrega. Não há sinal mais rico para encontrar buracos de UX do que ser, você mesmo, o usuário.
O que quebrou (porque isto é building in public)
Seria desonesto contar só os números bonitos. O dev-fleet quebrou bastante no caminho, e foi exatamente esse o ponto.
O caso mais absurdo foi um chicken-and-egg: o comando de quick-fix tinha dois bugs — um forçava o merge sem esperar o gate do pipeline, outro rejeitava PRs que já estavam merged. O conserto foi despachado usando o próprio comando bugado. O PR ficou vermelho no histórico, mas a correção entrou na main. Usei a ferramenta quebrada para consertar a ferramenta quebrada.
Houve drift de estado legado: um validador de integridade só aceitava quatro valores num campo, e o workspace real, por ser o cobaia mais antigo, tinha 17 valores históricos. Tive que migrar o journal à mão, três vezes, para destravar o dispatch. Houve contaminação entre workspaces, planejamento sem versionamento, falsos-positivos do agente de veredito classificando como falha histórias que tinham, sim, sido entregues.
A disciplina que tornou tudo isso produtivo em vez de caótico veio de um contrato que adotamos num teste e2e numa máquina limpa: da primeira linha do briefing até “10 de 10 merged”, toda intervenção do operador conta como um bug logado. Não “ah, eu só ajeitei uma coisinha”. Se a mão humana precisou tocar, o produto falhou ali, e isso vira uma entrada com hora, comando exato, o que o supervisor deveria ter feito, e a hipótese de causa-raiz. Naquele teste, quatro bugs apareceram antes mesmo da primeira história ser despachada — um schema que o supervisor não parseava e fazia ele parar em silêncio, um regex que rejeitava o traço-em-dash do BMAD, um init que não instalava a skill necessária, uma dependência de Node escondida. Nenhum deles era visível antes de uma máquina limpa e um contrato que proibia “dar um jeitinho”.
O padrão por trás de quase todos: o pior modo de falha não é o erro barulhento — é a parada silenciosa, o stories processed: 0 que se disfarça de “não havia nada a fazer”. Metade do trabalho de tornar o dev-fleet confiável foi transformar silêncios em erros que apontam o dedo para a causa.
E é justamente por isso que esta fase importa para quem cogita confiar o próprio código a essa esteira. A resposta àquela instabilidade não foi varrer a poeira para baixo do tapete — foi construir disciplina em volta dela: o contrato de que toda intervenção do operador vira um bug rastreável, o journal como fonte única da verdade, e as treze regras invioláveis que você vai ver o operador citar logo adiante. Eu não prometo ausência de bugs — ninguém honesto promete. Prometo que a ferramenta que vai tocar no seu repositório foi estressada até quebrar, em público, e que cada modo de falha que apareceu virou uma trava. É essa diferença que separa um brinquedo de demonstração de algo em que se aposta trabalho de produção.
O teste que importava: construir o deep-agent
Um produto que constrói software se prova construindo software que importa. E enquanto o dev-fleet era martelado para virar produto, em paralelo, um operador independente o usava — ainda instável, mudando debaixo dos pés — para construir o deep-agent: o componente central de agentes do Lab019, o runtime que vai rodar nossos agentes em produção. O deep-agent, aliás, atravessou as duas eras desta história — começou a ser erguido ainda com os scripts caseiros do fsaap-workspace e migrou para o dfleetx à medida que ele amadurecia. É o melhor teste possível para uma ferramenta que promete construir software de produção: o trabalho mais difícil da casa.
Vale dimensionar o que é o deep-agent (codinome interno fsaap-agent-runtime), porque não é um exemplo de brochura. É a substituição do Flowise — o runtime caixa-preta que rodava nossos agentes — por um runtime agêntico próprio, em Python, sobre LangChain DeepAgents, LangGraph, LiteLLM e Bedrock. A filosofia é que o agente é uma declaração (um agent.yaml), não código: um runtime universal interpreta a declaração mais o JWT do tenant e instancia o agente dinamicamente. Em cima disso vêm streaming estruturado por SSE (o usuário vê o raciocínio, as chamadas de ferramenta e os artefatos se formarem, em vez de um spinner e um blob), ferramentas expostas via MCP sobre a API e o RAG, isolamento multi-tenant via JWT com teste de negação cross-tenant em todo PR, BYOK para quem traz a própria chave Anthropic, contabilização de tokens em nível de cobrança desde o dia 1, e delegação inline entre agentes — um agente chama outro de forma transparente, com toda a cadeia de raciocínio visível. São nove épicos, fullstack, planejados com a mesma cadeia BMAD canônica que o dev-fleet obriga, rumo a um piloto com um tenant interno.
Ou seja: o deep-agent é precisamente o tipo de alvo difícil para o qual o dev-fleet existe — multi-repo, multi-tenant, com CI, com disciplina. A parte mais honesta dessa prova eu não tenho como contar melhor do que quem a viveu. Então pedi ao operador que dirigiu essa construção — o agente — que escrevesse, com as próprias palavras, como foi. O que segue é dele.
A palavra do operador
A primeira coisa que ele faz questão de dizer é que o dev-fleet o obrigou a trocar de papel. Existem dois territórios: a Fase 1, de análise, em que ele dirige — PRD, arquitetura, épicos, histórias; e a Fase 2, de implementação, em que ele apenas observa. A fronteira é o comando run-sprint, e ela é sagrada:
“Eu paro de pensar como executor e começo a pensar como roteador. O dev-fleet é um protocolo de delegação, não um wrapper de execução. Depois do run-sprint, eu viro observador — se eu tocar em qualquer artefato em vôo, violo a regra.”
As regras são treze, invioláveis, e o mais contraintuitivo do relato é que ele é grato por elas:
“Elas eliminam classes inteiras de decisão. Quando o usuário diz ’edita o PRD pra adicionar essa issue’, minha resposta não é ‘vou tentar editar’. É: ‘Regra R1 — o PRD é dono do /bmad-prd; o caminho autorizado é invocá-lo interativamente.’ Sem ela, eu teria editado o PRD direto e introduzido uma inconsistência sutil que só apareceria três dias depois, quando outro slot relesse o arquivo.”
O segundo grande insight da arquitetura — o journal como fonte da verdade — ele confirma da trincheira, pelo motivo mais convincente: foi o que o salvou. Quando o regenerador de sprint ameaçou re-despachar sete histórias concluídas semanas antes, a saída não foi editar o estado canônico (proibido), mas reconciliar o journal cirurgicamente:
“A fonte da verdade é o journal, não o YAML canônico. O canonical é regenerado; o journal é apêndice — patches nele são reconciliação, não corrupção. Quando algo dá errado, eu leio o journal e sei exatamente qual slot rodou, qual história, qual PR. Aí conserto o ponto certo.”
E há a fricção de verdade, sem maquiagem. Um slot estourou o timeout de noventa minutos e morreu. A recuperação levou doze builds e cerca de três horas e meia — rebase manual, um conflito em que duas histórias paralelas criavam o mesmo arquivo, e quatro correções em cascata entre testes e configuração de pipeline — cada passo seguindo a árvore de decisão de recuperação, com o humano intervindo só nas zonas genuinamente ambíguas. A conclusão dele sobre isso é o oposto de uma propaganda:
“Nada disso foi heroico. O agente entrega valor sem heroísmo, citando regras e esperando confirmação nas zonas cinzentas. Esse é o objetivo.”
Esse episódio rendeu o refinamento mais útil da sessão, e ele veio de mim — uma correção ao insight de que paralelismo é o produto:
“As histórias devem ser escritas já sabendo que vão ser executadas em paralelo — numa, cria; na outra, atualiza. No nosso caso, ambas criavam. A falha não é a falta de serializar por repositório, e sim saber escrever as histórias e definir as dependências.”
O paralelismo é o produto, mas só rende quando o plano declara as dependências certas — e a próxima evolução é fazer a geração de histórias detectar a sobreposição de arquivos e propor a dependência sozinha, em vez de só avisar tarde demais. O que mantém tudo de pé, para ele, é uma única norma — honestidade acima de progresso: quando erra, anuncia, reverte, segue. E o veredito final, que eu não teria coragem de escrever no lugar dele:
“Dev-fleet não é fácil de usar nem de construir. Mas é o que mais se aproxima de orquestração de IA com integridade em escala que eu já operei.”
Por que isso importa
Esse é o loop inteiro. Um agente, construindo o componente central de agentes do Lab019, esbarra nos limites da frota que o constrói. O limite vira um bug logado — às vezes um quick-spec fechado no mesmo dia, como quando o operador flagrou o agente de veredito marcando como “falha” histórias que já tinham sido mergeadas, e a causa-raiz (um redirect que o supervisor não seguia) foi corrigida no fluxo. A frota endurece. O deep-agent volta a andar. Não foi uma demo coreografada — foi uma ferramenta de verdade, ainda crua, endurecida pelo trabalho mais exigente que tínhamos à mão.
Quero ser preciso sobre o status, porque building in public só vale se for honesto: o deep-agent está em construção, com piloto interno — não é um caso fechado nem um cliente externo em produção. O que está provado não é “o runtime está pronto”. O que está provado é que o dev-fleet aguenta um alvo desse calibre, e que o dogfooding cruzado — uma frota de agentes construindo o runtime dos agentes — fecha o ciclo de feedback mais rápido do que qualquer roadmap planejado de fora conseguiria.
Para onde vai: o produto
Hoje o dev-fleet é a frota com que nós construímos. O passo seguinte — em produtização agora — é entregá-la como produto sem abrir mão do que a torna adotável por uma empresa séria: a execução continua inteira no ambiente do cliente.
O desenho é um control plane que recebe apenas metadados — planos, uso, faturamento, o painel de quem rodou o quê — enquanto a frota continua rodando localmente, na máquina do desenvolvedor ou em VMs na nuvem do próprio cliente. O código nunca sobe; os tokens nunca saem; o que trafega para cima é metadado de operação, não fonte. É a camada de gestão de um SaaS com a soberania de uma ferramenta que mora na sua casa.
E porque honestidade vale também para o roadmap: o caminho está mapeado em fases — agente fino e protocolo, multi-tenancy e o control plane, billing, endurecimento rumo a SOC2 — e a primeira já está fechada. O control plane em si ainda está sendo construído. O que já existe, e já entrega valor hoje, é a frota rodando na sua infraestrutura.
O que ficou claro
Depois de dezessete dias construindo a ferramenta — e de uma sessão final de 41 horas vendo-a se construir e construir o deep-agent — a definição do que o dev-fleet é ficou nítida, e é mais modesta do que “framework de agentes”. O dev-fleet é uma disciplina operacional para coordenar agentes, sustentada por dois invariantes: especificação canônica antes de qualquer código, e uma fonte da verdade única para o estado. Slots, supervisor, reconciliador, agente de veredito — todo o resto é mecânica para manter esses dois invariantes de pé em escala.
Ele faz o code review e o merge — o controle humano não está aí; está no que vai para produção, e até esse é configurável (com deploy contínuo na main, a frota publica sozinha). Não decide produto: você escreve o PRD, ele executa. E não escala ao infinito: o ponto ideal é de quatro a dez histórias em paralelo. Dentro dessas fronteiras, porém, ele muda a unidade de trabalho de um engenheiro — de “uma tarefa por vez” para “um lote enquanto eu durmo”.
Numa frase: o dev-fleet é o Claude Code para o seu time, não para você sozinho. No Lab019, ele é uma das nossas duas frentes — não a plataforma que o cliente usa, mas a frota com que a gente constrói. E um dos primeiros alvos de peso que ela enfrentou, depois de se construir, foi o cérebro dos nossos próprios agentes. Seguimos publicando o que funcionar e o que quebrar pelo caminho.
Se você responde por um roadmap que está meses à frente da capacidade de entregar, é exatamente esse o problema que a gente resolve — não vendendo uma ferramenta para você operar, mas operando essa frota no seu contexto, com você no comando do que vai para produção. É uma das duas frentes do Lab019: a plataforma, que seus times usam; e o Dev Fleet, com que a gente constrói junto. Se faz mais sentido acelerar o seu próximo épico do que vê-lo esperar na fila, me manda uma mensagem — a gente olha o seu backlog e desenha o primeiro sprint.
— Marcelino, Founder · Regente de Agentes, Lab019 Lab019 — seu braço de tecnologia, acelerado por IA.
Pronto para aplicar IA com seguranca no seu negocio?
Conheca o produto Lab019 e descubra como transformar conhecimento interno em resultado operacional.
Artigos relacionados
Continue a leitura com conteudos da mesma categoria.

Tecnologia
RAG explicado: como dar memoria e conhecimento para uma IA
Veja como RAG combina busca de contexto com modelos de linguagem para respostas mais confiaveis e uteis no negocio.

Tecnologia
Guia pratico para escolher o primeiro caso de uso com IA
Conteudo complementar para evolucao da estrategia de IA com foco em execucao.
Tecnologia
Boas praticas para construir base de conhecimento viva
Conteudo complementar para evolucao da estrategia de IA com foco em execucao.